Amazon propose une sécurisation a priori treès avancée de son hébergement, via la répartition de ses DataCenter : Amazon est découpé en "régions" réparties sur le globe (Europe, Asie, US-Est, ...). Répliquer une application entre régions est en principe le plus haut niveau de High-Availability que vous pourriez mettre en oeuvre, mais introduit évidemment des latences et des coûts réseau élevés. Amazon divise alors chaque région en "availability zones", chaque zone étant indépendante : datacenter géographiquement séparé, alimentation électrique différence, accès réseau différent, etc... tout en ayant une inter-connexion réseau à très haut débit. D'après la documentation Amazon, répartir une application sur plusieurs zone est donc la solution garantissant une disponibilité quasi infaillible.
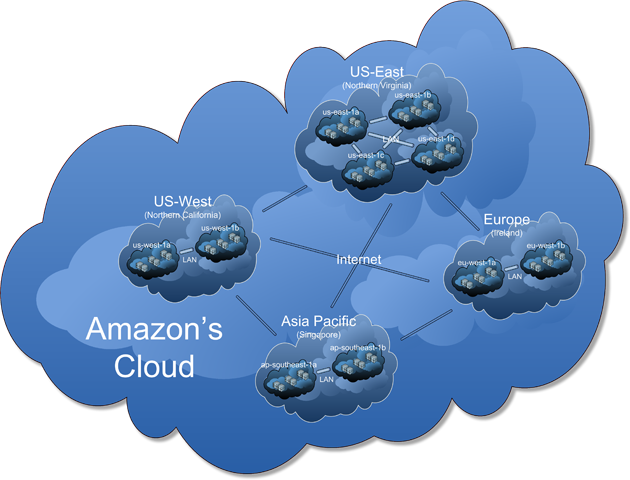
Plus d'infos ici si le sujet vous intéresse, et par exemple cet article sur l'utilisation des zones pour mettre en place une architecture "designed to fail".
Sauf que "quasi infaillible", ce n'est pas une garantie totale. Il y a quelques jours, comme c'est déjà arrivé en début d'année dernière, les différents datacenter d'une zone sont tombés ensembles, réduisant à néant toutes les stratégies de failover.
Voici la réponse d'Amazon :
6:09 PM PDT We want to provide some additional information on the Internet connectivity interruption that impacted our US-East Region last night. A networking router bug caused a defective route to the Internet to be advertised within the network. This resulted in a 22 minute Internet connectivity interruption for instances in the region. During this time, connectivity between instances in the region and to other AWS services was not interrupted. Given the extensive experience that we have running this router in this configuration, we know this bug is rare and unlikely to reoccur. That said, we have identified and are in the process of deploying a mitigation that will prevent a reoccurrence of this bug from affecting network connectivity.
Un putain de bug tordu dans un routeur ... aucun doute qu'Amazon va tirer des leçons de ces soucis et apporter une solution pour rendre ses zone (encore) plus indépendantes. Aucun doute aussi que de nombreux services Cloud vont apprendre de ces expériences et renforcer leur fiabilité et la redondance de leur architecture.

Quoi qu'il en soit, si beaucoup pointent du doigt une défaillance du Cloud qui promettait monts et merveilles, on oublie que ces pannes démontrent surtout une disponibilité à 99,99% et une grande efficacité dans la rétablissement du service. A comparer avec le niveau de service que vous pouvez obtenir avec un hébergement traditionnel, et aux coûts associés...
Par contre, ceux qui sont déjà dans le Cloud se posent la question de la validité du modèle de zones d'Amazon, puisqu'en 12 mois on a déjà eu deux pannes majeures de ce modèle (voir par exemple http://www.networkworld.com/news/2011/042111-amazon-ec2-zones.html).
Par contre, ceux qui sont déjà dans le Cloud se posent la question de la validité du modèle de zones d'Amazon, puisqu'en 12 mois on a déjà eu deux pannes majeures de ce modèle (voir par exemple http://www.networkworld.com/news/2011/042111-amazon-ec2-zones.html).

Lors de mes présentations sur le Cloud dans les Java User Group, je ne cherche pas à occulter la réalité de cette nouvelle approche de l'informatique. Non, le Cloud n'est pas la silver-bullet qui va résoudre tous vos soucis. D'où l'importance d'y aller aujourd'hui, même avec de petites applications de test, pour vous faire votre propre expérience des contraintes techniques, de la qualité de service, des offres de chaque fournisseur et des coûts associés.
Pour les utilisateurs de CloudBees, nous n'avons pas de solution officielle clé en main pour assurer du 99,9999999999%. Par contre, depuis l'annonce AnyCloud, qui vous permet de déployer votre application sur plusieurs DataCenter, éventuellement via des fournisseurs différents, rien ne vous interdit de mettre en oeuvre votre propre architecture hautement redondante. Nul doute, après cette nouvelle panne d'Amazon, 1er fournisseur IaaS du Cloud, qu'on trouvera rapidement des témoignages très intéressants sur le sujet.

0 commentaires:
Enregistrer un commentaire